
コード品質の話は、すぐに流儀の話になりがちです。DIを使うか、レイヤーを切るか、どの設計原則を守るか。もちろんそれらは大事ですが、実務で先に知りたいのは別です。どんなコードが壊れやすいのか。何を見れば、次に事故りそうな場所を早く見つけられるのか。その観点が先に必要です。
この記事では、コード品質とバグの関係を、循環複雑度、変更頻度、結合の見えやすさという3つの軸で整理します。そのうえで、DIは品質を上げる手段にも、逆に依存を隠してバグを増やす反例にもなり得ることを見ます。最後に、実務で使いやすい「ほどほど」な品質改善の進め方をまとめます。
コード品質は大事ですが、単一指標では測れません
まず押さえたいのは、コード品質とバグには確かに関係がある一方、1つの指標だけで全部は説明できないことです。
ここでいう定量のエビデンスは、主に2種類あります。1つは、ある指標と欠陥件数や欠陥密度の相関です。もう1つは、過去の変更履歴やメトリクスから、欠陥が多いモジュールをどれくらい当てられるかという予測性能です。逆に言うと、論文が「循環複雑度11以上は危険」のような万能なしきい値を直接与えているわけではありません。
循環複雑度の出発点になったMcCabeの論文は、複雑さは行数ではなく、分岐の構造で決まると説明しています。分岐が増えるほど、通り得る経路も増えます。つまり、理解とテストの両方が難しくなります。A Complexity Measure
ただし、複雑度だけを見れば十分、とは言えません。FentonとOhlssonは大規模な商用ソフトウェアを調べ、よく使われる複雑度指標だけでは、故障しやすいモジュールをうまく予測できるとは言えないと報告しています。Quantitative analysis of faults and failures in a complex software system
一方で、変更頻度はかなり強い手掛かりになります。NagappanとBallはWindows Server 2003の事例で、単純な変更量ではなく、サイズや期間と組み合わせた相対的なコード変更量が、欠陥密度の予測にかなり有効だと示しました。論文では、故障しやすいバイナリとそうでないバイナリを89.0%の精度で判別できたとしています。Use of relative code churn measures to predict system defect density
設計や実装の悪い兆候を調べた研究も同じ方向を示しています。Palombaらの大規模実証では、長いコードや複雑なコードに関係する悪い兆候は広く見られ、そうした兆候を持つクラスは変更されやすく、バグも入りやすいと報告されています。Palombaらの研究
依存やサイズについても、近い傾向があります。Aggarwalらの追試研究では、Javaアプリケーションのクラスを対象に、オブジェクト指向メトリクスから欠陥クラスを90%以上の精度で予測できたと報告されています。特にimport couplingとサイズの指標が、欠陥の出やすさと強く関係していました。Aggarwalらの研究
ただし、ここでも過信は禁物です。Hallらは、3つのオープンソースシステムで5種類の設計上の悪い兆候と不具合の関係を負の二項回帰で分析し、有意な関係が見つかっても、その効果量は常に10%未満だったと報告しています。つまり「悪い兆候を見つけたら全部直せば安全になる」という話ではありません。Hallらの研究
ここから言えるのは単純です。コード品質を見るときは、1つの流行語や1つの指標に寄せないほうがよいということです。実務では、複雑さ、変更頻度、依存の見えやすさを合わせて見たほうが、ずっと事故に近づけます。
実務でまず見るべきは3つの軸と1つの補助指標です
品質改善を始めるとき、全部のコードを同じ温度で見ないほうが効率的です。まずは、循環複雑度、変更頻度、依存の見えやすさの3軸でホットスポットを見つけます。サイズと責務の広さは、その3軸を悪化させやすい補助指標として扱うと整理しやすくなります。
この整理は、次の図で見ると分かりやすいです。
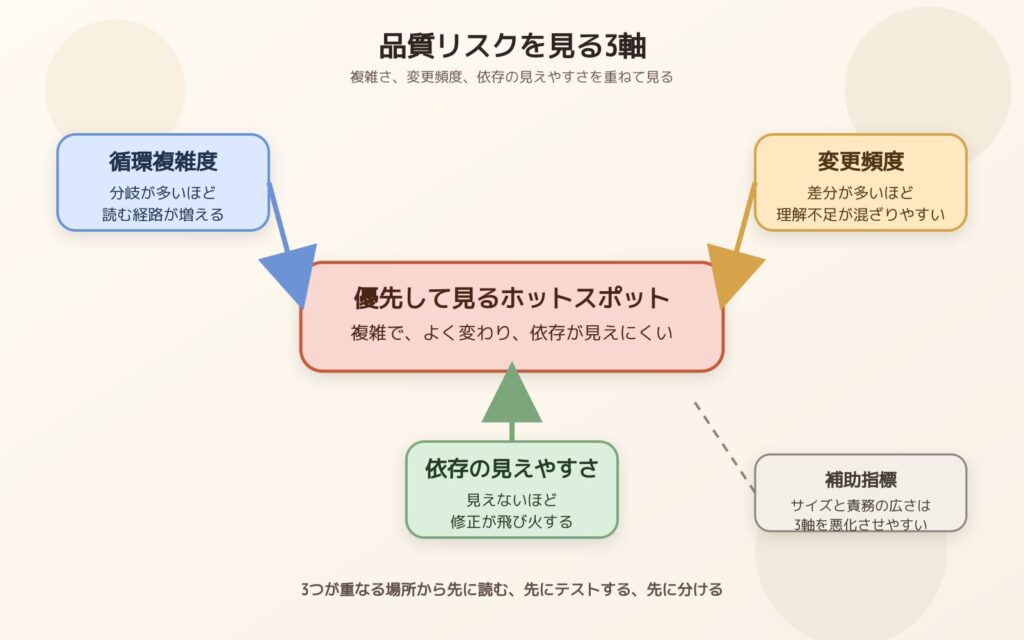
3つが重なる場所ほど、先に読む、先にテストする、先に分ける価値が高くなります。
実務で数値に落とすならこう見ます
品質の話を感覚で終わらせないために、まずは次の4つを同じ物差しで見ます。ここで挙げる数字は自然法則ではなく、レビュー対象をそろえるための実務目安です。
論文が直接支えているのは、これらの指標と欠陥の相関や予測性能です。表のしきい値は、その結果を現場運用に落とすための目安として置いています。
| 項目 | 何を数えるか | まず置く目安 |
|---|---|---|
| 循環複雑度 | 関数ごとの分岐経路数 | 1から5は通常、6から10は注意、11から14は分割候補、15以上は優先してテストと分割を検討 |
| 変更頻度 | 直近90日か180日のコミット回数と相対変更量 | 90日で3回以上なら注視、10回以上ならホットスポット候補 |
| 依存の見えやすさ | 明示依存数、隠れた依存数、修正時の波及ファイル数 | 隠れた依存は0を基本、明示依存が5個超なら責務点検、1つの修正で5ファイル超に波及するなら結合を疑う |
| サイズと責務の広さ | 関数行数、クラス行数、公開メソッド数、変更理由の種類 | 関数50行超、クラス300行超、公開メソッド10個超、変更理由3種類超は分割候補 |
「数えて終わり」にしないことも大事です。どこから手を入れると元が取りやすいかを決めておくと、運用しやすくなります。
| 指標 | 効果 | 着手の目安 | 先にやること |
|---|---|---|---|
| 変更頻度 | 強 | 直近90日で10回以上変わる、または相対変更量が0.5超 | 先にテストを足す。変更点を1か所に寄せる。安定した境界を作る |
| 依存の見えやすさ | 強 | 隠れた依存が1つでもある、または1つの修正で5ファイル超か3層以上に波及する | 隠れた依存を外へ出す。service locatorやグローバル参照をやめる。依存を宣言で見せる |
| 循環複雑度 | 中 | 11以上で変更頻度も高い、または15以上 | まず分岐を減らす。境界条件のテストを増やす。ネストを浅くする |
| サイズと責務の広さ | 弱 | 関数80行超、クラス300行超、公開メソッド10個超のどれかに加えて、他の指標も悪い | 先に責務を分ける。公開面を絞る。初期化とビジネスロジックを分離する |
要するに、最初に着目すべきは変更頻度と依存の見えやすさです。複雑度はその次で、サイズは単独ではなく補助指標として使うほうが、手間に見合いやすいです。
単独の数字ではなく、掛け合わせで優先順位を決めます。例えば、循環複雑度が12でも半年ほとんど触られていない関数より、循環複雑度が8で直近90日に12回変わり、隠れた依存が2つある関数のほうを先に見るべきです。
循環複雑度
循環複雑度は、関数やメソッドの中にどれだけ分岐経路があるかを見る指標です。高いから即バグ、低いから安全、とは言えません。ただ、分岐が増えると、レビューで追うべき経路とテストで押さえるべき経路が増えるのは事実です。
定量の根拠としては、McCabeが分岐構造を複雑さとして定義し、FentonとOhlssonがその後の実証で、複雑度単独では故障しやすいモジュールの予測力が強くないことを示しています。つまり、循環複雑度は単独の判定器ではなく、レビュー密度を上げるためのシグナルとして使うのが妥当です。A Complexity Measure / Quantitative analysis of faults and failures in a complex software system
実務では、1から5は普通、6から10は境界条件の洗い直し、11から14は分割候補、15以上は優先してテストを厚くする、くらいで十分です。深いネスト、長い条件分岐、例外ケースの詰め込みは、まず分解候補です。
大事なのは、複雑度を行数の代わりに使うことです。30行でも複雑度2なら読みやすいことがありますし、15行でも複雑度12なら危ないことがあります。レビューでは、複雑度11以上の関数だけ別枠で見る運用にすると、かなり効率が上がります。
変更頻度
壊れやすいのは、複雑なコードだけではありません。頻繁に触られるコードは危ないです。仕様追加や緊急修正の続く場所では、理解不足のまま差分が積み上がりやすくなります。
ここで効くのは、絶対的な変更行数より相対変更量です。200行のファイルに100行の差分が入るのと、5000行のファイルに100行の差分が入るのは別物だからです。簡単には、期間内の追加行数と削除行数の合計を現在の行数で割れば見られます。
定量の根拠としては、NagappanとBallがWindows Server 2003のバイナリ群を対象に、相対変更量が欠陥密度を強く予測したと報告しています。さらに、欠陥を起こしやすいバイナリとそうでないバイナリを89.0%の精度で判別できたとしています。変更頻度は、いまでも実務で最も使いやすい欠陥予測の手掛かりの1つです。Use of relative code churn measures to predict system defect density
実務では、直近90日で3回以上変わったファイルを注視し、10回以上変わったファイルをホットスポット候補にすると扱いやすいです。相対変更量でも、同じ期間にファイル全体の半分以上が入れ替わるなら危険信号です。中くらいの複雑度でも、変更頻度の高い場所は優先して見る価値があります。逆に、少し複雑でも長く安定しているコードは、急いで触らないほうが安全です。
結合の強さと依存の見えやすさ
変更の影響範囲が読みにくいコードは、バグを埋め込みやすくなります。どこが何に依存しているかが見えないと、1か所の修正が別の場所へどう飛ぶかを予測しにくいからです。
依存関係の見通しやすさを、そのまま数値で測る定番指標はあまりありません。ただ、結合度や変更の波及範囲を見れば、近い傾向はつかめます。Aggarwalらは、import couplingとサイズが欠陥の出やすさに強く関係すると報告しています。つまり、依存をむやみに減らすことより、結合を追える形に保つことのほうが大事です。Aggarwalらの研究
依存の見えやすさは主観に見えますが、3つの数字でかなり揃えられます。1つ目は明示依存数です。コンストラクタ引数や必須設定が5個を超えたら責務過多を疑い、8個を超えたら分割候補です。2つ目は隠れた依存数です。メソッドの中でDIコンテナから解決する、グローバル状態を読む、静的な共有設定を引く。こうした依存は0を基本にします。3つ目は波及ファイル数です。同じユースケース修正で毎回5ファイル以上、3層以上に差分が飛ぶなら、依存の向きか境界の切り方を疑うべきです。
グローバル状態、暗黙の設定参照、深い層の奥での動的解決、巨大な共有オブジェクト。こうした構造は、一見すると便利でも、変更時の見通しを悪くします。依存を減らすことより、隠れた依存を減らして、必要な依存が外から読める形へ寄せることのほうが実務では重要です。
サイズと責務の広さ
長いメソッドや大きいクラスは、それだけで悪ではありません。ただ、責務が混ざりやすく、分岐や依存が増えやすいので、複雑度や結合の悪化と一緒に現れやすいです。
ここでの定量根拠も、サイズ単独の万能性ではなく、サイズと結合度を含めた欠陥予測です。Palombaらは長いコードや複雑なコードに関係する悪い兆候を持つクラスのほうが変更されやすく、バグも入りやすいと示しました。Aggarwalらも、サイズ指標が結合度と並んで欠陥予測に効くと報告しています。Palombaらの研究 Aggarwalらの研究
目安としては、関数50行超で要点検、80行超で分割候補、クラス300行超で責務整理を検討、公開メソッド10個超で外向きの責務が広すぎないかを見る、くらいから始めると扱いやすいです。変更理由が3種類以上あるクラスや、コンストラクタと初期化コードだけで40行を超えるクラスも同様です。
まず疑うべきなのは、レビューで何度も説明を求められるクラスです。サイズそのものより、長さのせいで責務の数が見えなくなっていないかを確認するほうが重要です。責務の切り出しを考える価値があります。
DIは万能薬ではなく、依存の見えやすさを改善できるときだけ効きます
ここでDIの話が出てきます。DIはコード品質そのものではなく、依存の見えやすさを改善するための手段の1つです。
Martin Fowlerは、Dependency Injectionの要点を、設定と利用を分けることに置いています。コンストラクタ注入の利点は、そのオブジェクトに何が必要かを宣言だけで読めることです。Inversion of Control Containers and the Dependency Injection pattern
この形なら、依存関係は前に出ます。レビューとテストの両方で、不足している依存や責務の多さに気づきやすくなります。MicrosoftのDIガイドも、注入される依存が多すぎるクラスを、責務過多の兆候として挙げています。Dependency injection guidelines
逆に、DIコンテナを業務コードの中へ持ち込むと話は変わります。必要なサービスをその場で解決し始めるからです。Mark Seemannが示したService Locatorの例が分かりやすいです。見かけ上は単純なクラスでも、内部で必要な依存を都度取得します。すると、登録漏れは実行時例外へ変わります。依存追加の破壊的変更も、外から見えにくくなります。
Microsoftも、GetServiceのようなservice locatorパターンや、実行時に依存を解決するfactoryの注入を避けるよう勧めています。具体的な反例も明記しています。async factoryはデッドロックを招きます。root containerからのIDisposable解決はメモリリークにつながります。singletonがscoped serviceを抱えると、lifetime不整合も起きます。Dependency injection guidelines
ここは大規模な欠陥密度研究というより、障害の起き方が追える種類の根拠です。依存を隠すと、どの条件で実行時に壊れるかを静的に読めなくなります。つまりDIの話は、欠陥予測の統計というより、欠陥を埋め込みやすい仕組みの説明だと捉えたほうが正確です。
つまり、DIが品質に効くのは、依存を見えやすくするときだけです。依存を隠し始めた瞬間、それは品質改善ではなく、ただの間接化になります。
ほどほどなコード品質とは何か
ここまでを踏まえると、目指すべきものは「抽象化を増やすこと」ではありません。壊れやすい場所を早く見つけ、変更の影響を読みやすくし、レビューとテストの負担を下げることです。
実務では、次の進め方がかなり現実的です。
指標は合否ではなく、レビューの入口にする
循環複雑度が高い、変更頻度が高い、依存が多い。こうした数字は、その場でリファクタリングを強制するためではなく、どこを丁寧に見るかを決めるために使うほうがうまく回ります。例えば、各項目を0点から2点で置いて、合計4点以上を重点レビュー対象にするだけでも、優先順位の議論はかなり揃います。
ホットスポットから直す
壊れやすいのは、複雑で、よく変わり、依存が見えにくい場所です。逆に言えば、その3つが重なる場所から直すと効率が良いです。見た目が悪いだけの安定コードを片っ端から掃除するのは、たいてい割に合いません。
まず分岐を減らし、その後で抽象化する
複雑な条件分岐をそのまま抽象化すると、読みにくさだけが別の場所へ移ることがあります。先に責務を分け、分岐を減らし、境界条件を整理してから抽象化したほうが、結果は安定します。
依存関係は宣言で見える形に寄せる
関数引数、コンストラクタ、明示的な設定。こうした場所で依存が見えるだけで、レビューとテストはかなり楽になります。逆に、グローバル参照やcontainer解決が混ざると、変更の影響は一気に追いにくくなります。
次の変更が楽になるかで判断する
品質改善は美化活動ではありません。次に同じ場所を触る人が、短く、正確に、安全に変えられるか。その観点で判断したほうが、過剰設計や放置に寄りにくくなります。
おわりに
コード品質を考えるとき、DIだけを見ても足りません。先に見るべきなのは、分岐の多さ、変更の多さ、依存の見えやすさです。循環複雑度は有用ですが、それだけで十分ではありません。変更頻度だけを見ても足りません。パターンを採用していても、依存が隠れていれば危ないままです。
ほどほどなコード品質とは、きれいに見えることではありません。壊れやすい場所が見え、変更の影響が読みやすく、テストとレビューが現実的なコストで回ることです。DIはその中で効く場面もありますが、あくまで道具の1つです。主役は、複雑さ、変更頻度、依存の見えやすさの3つです。
